
My first experience with AWS Lambda
I've been wondering if I can tame Twitter a bit by cleaning up my timeline. Using AWS Lambda and the Ephemeral Go package, I think I've found a good start.

Being a minimalist
When my wife and I married and moved into our first home 13 years ago, I brought two boxes of "stuff" along with some clothes, a computer and a bike. That's it. Sure I've accumulated more since then - it's impossible to own a home and not unless you hire every job out - but I could probably still fit the stuff that's just mine into the trunk of a car.
I'm a minimalist. I appreciate organization. I like finding patterns and purpose in things. As time goes on, my feeling that social media is neither minimalist, organized, nor purposeful is reinforced again and again. Facebook's numerous security gaffes have caused me to think about how much digital litter I've left strewn around the Internet, and whether I can make these sites more purposeful or should just cut them out of my life altogether.
Too much digital "stuff" ... aka taming the beast
Twitter's been on my radar too, but I wasn't sure what to do with it. I like it for the great techie posts people share, but it's generally a stress-inducing time-vortex. I just found out you can see your friends tweets from 10 years ago, and that's horrifying to me. I don't want or need to know everything people said last week, let alone last decade. And it hit me that what bugs me about this stuff is all the stuff. Anything older than a couple weeks is practically worthless - and yet it remains forever.
I just about deleted my account in disgust, when by chance I stumbled across a thoughtful article by Vicky Lai entitled "Why I'm automatically deleting all my old tweets, and the AWS Lambda function I use to do this". She seems to have had similar thoughts to mine, but shares it more eloquently and actually took steps to correct it. Here's one of my favorite excerpts:
If you wouldn't assume that a notepad scribble from last week or a crayon drawing from decades ago reflects the essence of who someone is now, why would you assume that an old tweet does?You are not the same person you were last month — you've seen things, read things, understood and learned things that have, in some small way, changed you. While a person may have the same sense of self and identity through most of their life, even this grows and changes over the years. We change our opinions, our desires, our habits. We are not stagnant beings, and we should not let ourselves be represented as such, however unintentionally.
And so she created a Go package called Ephemeral, and combined it with AWS Lambda to create a great little tweet-cleaning service that you can schedule to run as often as you'd like... for free!
Compiling Ephemeral
Vicky's article has all the details, so I'll just add a few of my own that weren't included. She seems to have experience with Go, but this was my first "go" at it (ugh, sorry). Anyway, here's how to install it and compile the package:
- Download Go for your operating system.
- Create a local folder and copy "main.go" into it from Vicky's GitHub repo.
- Open a command prompt, navigate to the folder, and "get" the dependencies:
go get github.com/ChimeraCoder/anacondago get github.com/Sirupsen/logrusgo get github.com/aws/aws-lambda-go/lambda - Compile the package with
go build main.go. (If you're on a mac, you may have to useGOOS=linux go build main.go- more on that below.) - You should now have an executable called "main". Compress it into a zip file.
If you want to learn more about Go, this might be a good starting point: Go by Example
Running the Lambda
Amazon has a free tier that's quite generous. When you setup a Lambda function it defaults to 128 MB memory, and if you leave it at that you apparently get 3,200,000 free seconds a month. And since there's only 2.6 million seconds in a month, you could basically leave a single copy of your job running forever. 😮
Vicky's got the details for setting up AWS Lambda too, so again I won't reiterate it all here except to add a few personal notes.
Naming things
When you create a new Twitter app, the name doesn't matter but it does have to be unique system-wide (not just unique in your account). When you create a new Lambda function, that name doesn't matter either.
Keys and tokens
Ephemeral expects your AWS Lambda job to provide it with a few pieces of data from your Twitter account. To get them, generate an "access" token under the "Keys and Access Tokens" section, and note these four pieces of data: Consumer Key, Consumer Secret, Access Token, and Access Token Secret
Lambda configuration
When you upload your zip file in the "Function codeInfo" section, type "main" in the "Handler" field. Maybe it was mentioned in the original post, but it took me a minute to figure it out.
And when you get to the part about setting up a cron job, consider setting it to something frequent at first to do the initial cleanup, like cron(0/1 * * * ? *) to run it once a minute... or just hit the TEST button multiple times.
Rate limiting
Something to think about when setting up your cron job is rate limiting. While AWS Lambda lets you run a job near continually, hitting Twitter's API too aggressively could cause problems. The limits seem fairly well documented, with getting a user's timeline capped at about 900 requests per 15 minutes, and although destroying a tweet doesn't have a specific number it seems reasonable to assume it's the same as getting a tweet which is also 900 requests per 15 minutes.
So play it safe and don't run your job more than, um... once a second. Heh, okay that seems pretty reasonable actually.
Gotchas
I ran into a few issues when I tried to implement this... maybe including them will save you a few minutes!
exec format error
When I built the Ephemeral package and uploaded it to AWS, then tried to test it out, I got a PathError error that said "fork/exec /var/task/main: exec format error".
After finding a post that described the fix (I got the error on a Mac, as did the author), I went back to the command line and ran GOOS=linux go build main.go and uploaded it again. Success! Well, almost...
It's 72h, not 72! (aka understand the code you're running)
When you enter a value for the MAX_TWEET_AGE environment variable, make sure you include an 'h' with your hour value! Vicky clearly states that it's "the maximum age of the tweets you want to keep, represented in hours, like 72h" (emphasis mine), but for some inexplicable reason I just figured a number would be fine, so I put in 168 to keep one week of tweets.
Well, the time.ParseDuration package requires a time unit to be specified; without one, it just converts the string to a 0 instead of throwing an exception... doh. That mistake cost me a few recent tweets - luckily, just a few since the timeout for the function was still set to 3 seconds (more on that below). Oh well, they weren't that fantastic anyway. 😜
Update: The time.ParseDuration method does return an error if there is one - it's just being ignored in the code below. It'd be a good idea to check it, and doing so might've alerted me to a problem earlier! (Thanks Raphaël Pinson for pointing this out.)
To try it out yourself, either copy the code below or run it online.
package main
import (
"fmt"
"time"
)
func main() {
h1, _ := time.ParseDuration("72h")
fmt.Println(h1) // 72h0m0s
h2, _ := time.ParseDuration("72")
fmt.Println(h2) // 0s
}
Change the Timeout
I mentioned being saved by the short default timeout. Once I fixed the hours to be a week (168h), I tried running it a couple times with the TEST button and after about 5 tweets it would show an error on the AWS Lambda page:
{
"errorMessage": "2018-05-26T12:36:04.847Z 592b2d54-60e1-11e8-b21d-3dc5a12e6b2b Task timed out after 3.00 seconds"
}
There's a "Basic settings" panel in the Lambda screen, with a default timeout value of 3 seconds. Change that to something larger. I changed it to 3 minutes, but after testing the run multiple times, it ran in under 15 seconds and showed a success screen instead. Yay!
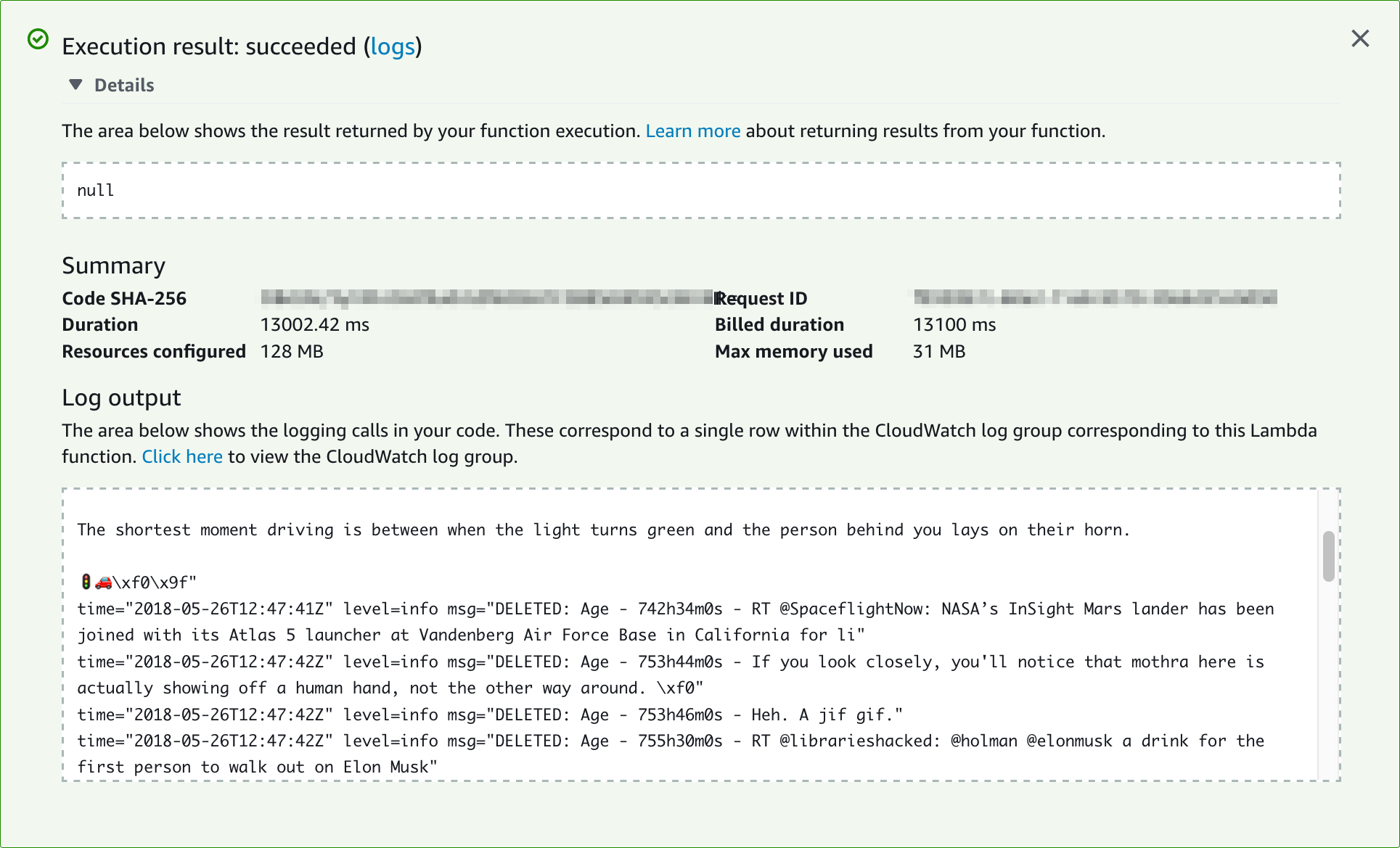
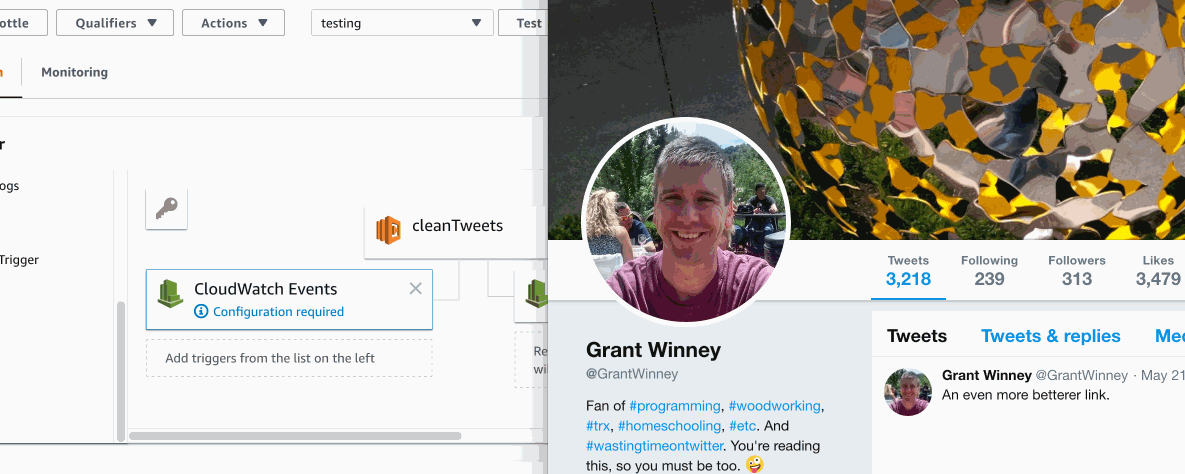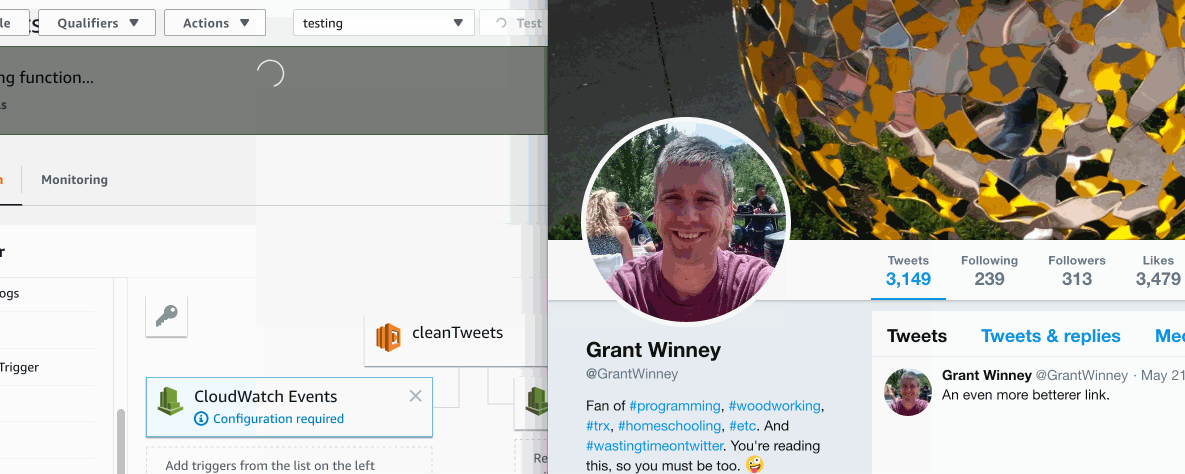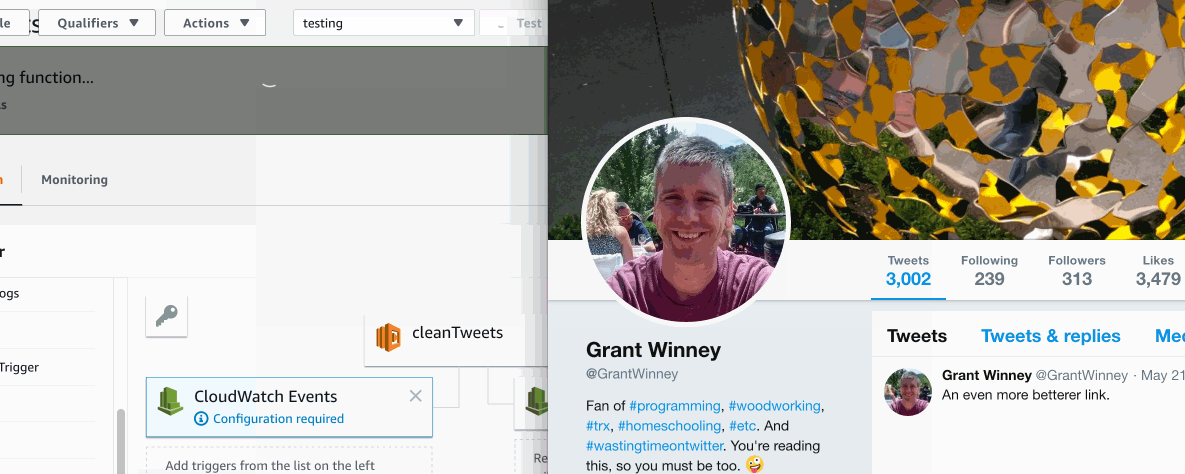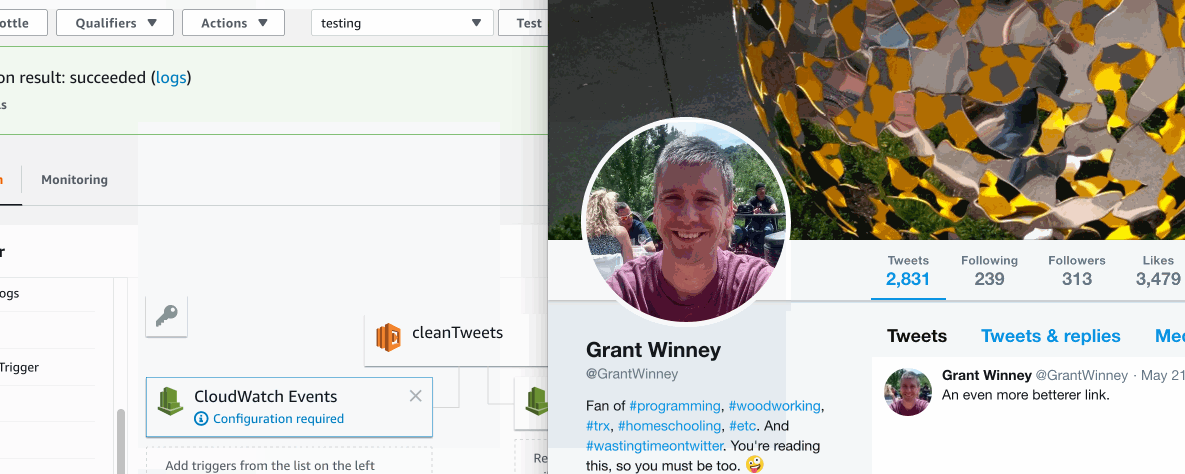
Seeing it in action
Click here to see it in action. It's an animated 2mb gif, and I don't want to destroy anyone's data plan... or cause this page to load horrendously slowly.
{kind=link}
Extending Ephemeral to clean up "Likes" too
This is a neat example of open source in action - building something useful in layers, relying on other projects - and potentially providing a foundation for future projects too. Ephemeral makes it possible to cleanup your tweets on a schedule with Lambda, by extending the Harold package which provides a series of functions like cleaning up tweets and more, by extending the Anaconda package which brings the Twitter API to the Go language.
I decided to extend it further, to clean up my "likes" / favorites as well. There's a function called "GetFavorites" in Anaconda's favorites.go file, which uses Twitter's favorites/list API endpoint. This one is more rate-limited, at 75 requests every 15 minutes, or once every 12 seconds. There's also a favorites/destroy API endpoint for unliking, which is implemented in Anaconda's tweets.go file... possibly the same rate limit?
I added a new environment variable to the Lambda job called MAX_FAVORITE_AGE for maximum favorite age, and set it to 2 weeks (336h). I sometimes use favorites as bookmarks, but I figure (a) if I haven't addressed it in 2 weeks I've forgotten about it, and (b) it's just another indicator of how I once felt which might not be how I feel anymore.
Then I lightly modified Vicky's package with two new functions based off hers. Actually, not much changed, since the favorites end point returns tweet objects as well.
func getFavorites(api *anaconda.TwitterApi) ([]anaconda.Tweet, error) {
args := url.Values{}
args.Add("count", "200") // Twitter only returns most recent 20 tweets by default, so override
timeline, err := api.GetFavorites(args)
if err != nil {
return make([]anaconda.Tweet, 0), err
}
return timeline, nil
}
func unfavorite(api *anaconda.TwitterApi, ageLimit time.Duration) {
favorites, err := getFavorites(api)
if err != nil {
log.Error("Could not get favorites")
}
for _, f := range favorites {
createdTime, err := f.CreatedAtTime()
if err != nil {
log.Error("Couldn't parse time ", err)
} else {
if time.Since(createdTime) > ageLimit {
_, err := api.Unfavorite(f.Id)
log.Info("UNFAVORITED: Age - ", time.Since(createdTime).Round(1*time.Minute), " - ", f.Text)
if err != nil {
log.Error("Failed to unfavorite! ", err)
}
}
}
}
log.Info("No more tweets to unfavorite.")
}
And then in the ephermal function that kicks it all off, I added two lines right under deleteFromTimeline():
hf, _ := time.ParseDuration(maxFavoriteAge)
unfavorite(api, hf)
Final thoughts
- I don't use moments at all, but I suppose you could extend functionality to deal with those too. 🤷♂
- I've reduced my tweets from about 3600 to 18 (and "likes" from about 5k to 359) from the last two weeks. Nice!
- I decided to keep two weeks of tweets instead of one, in case someone else is favoriting my tweet to bookmark it. But let's face it... after a couple weeks, they aren't going to remember it anymore than I will!
Comments / Reactions